数据库是Web开发中必不可少的一环,需要加强基础知识的学习和总结项目中出现的问题。难点主要在索引和分布式事务上,由于本人项目过程中使用的数据库多为MySQL和MariaDB,所以以下内容所使用的数据库环境均为MySQL
1. 数据库底层原理
1.1 数据存储方式
数据库中InnoDB和MyISAM存储引擎底层采用的存储方式为B+树,下面列举一下各个数据结构在数据存储时的演变过程。
- 数组:查询快,插入速度慢;
- 链表:查询慢,插入速度快;
- 二叉树:查询速度快,插入速度快,但是极端情况会变成链表,会大幅降低查询效率,例如树的节点为1(根节点)、2、3、4、5、6时且一个节点只有两个子节点存储效率太差;
- HASH表:将数据进行HASH运算,将运算完成后的结果存入地址,当存在碰撞时,将地址中的数据以链表的形式存储,缺点因为数据是计算后存储的,所以在范围查询时会效率低下,一般用于Memory引擎(一种完全存储在内存中的存储引擎);
- 红黑树:查询速度快,插入速度慢,使用树旋转优化了二叉树的极端情况,也就是当存在1、2、3、4、5、6时,会将根节点优化为3,然后层级降低为三层,但是频繁旋转的时候会导致插入速度较慢;
- B树:查询速度快,插入速度快,使用B树将子节点中的内容进行范围划分,且固定层级为三级。但是其中的数据都存在节点内,所以节点数据存储量太小,内存加载数据页时可容纳的数据也较少;
- B+树:查询速度快,插入速度快,在具备B树所有优点同时还将数据存入子节点,相邻的叶子节点之间头尾相连,在数据被使用时那么它附近的数据也会被使用,可以预加载到内存中;
在不同的存储引擎中B+树的存储方式也有所不同,InnoDB是采用聚集索引,MyISAM是采用非聚集索引。InnoDB有且必须要有一个聚集索引,一般是主键,没有主键则是第一个非空字段。
1.2 主要构成
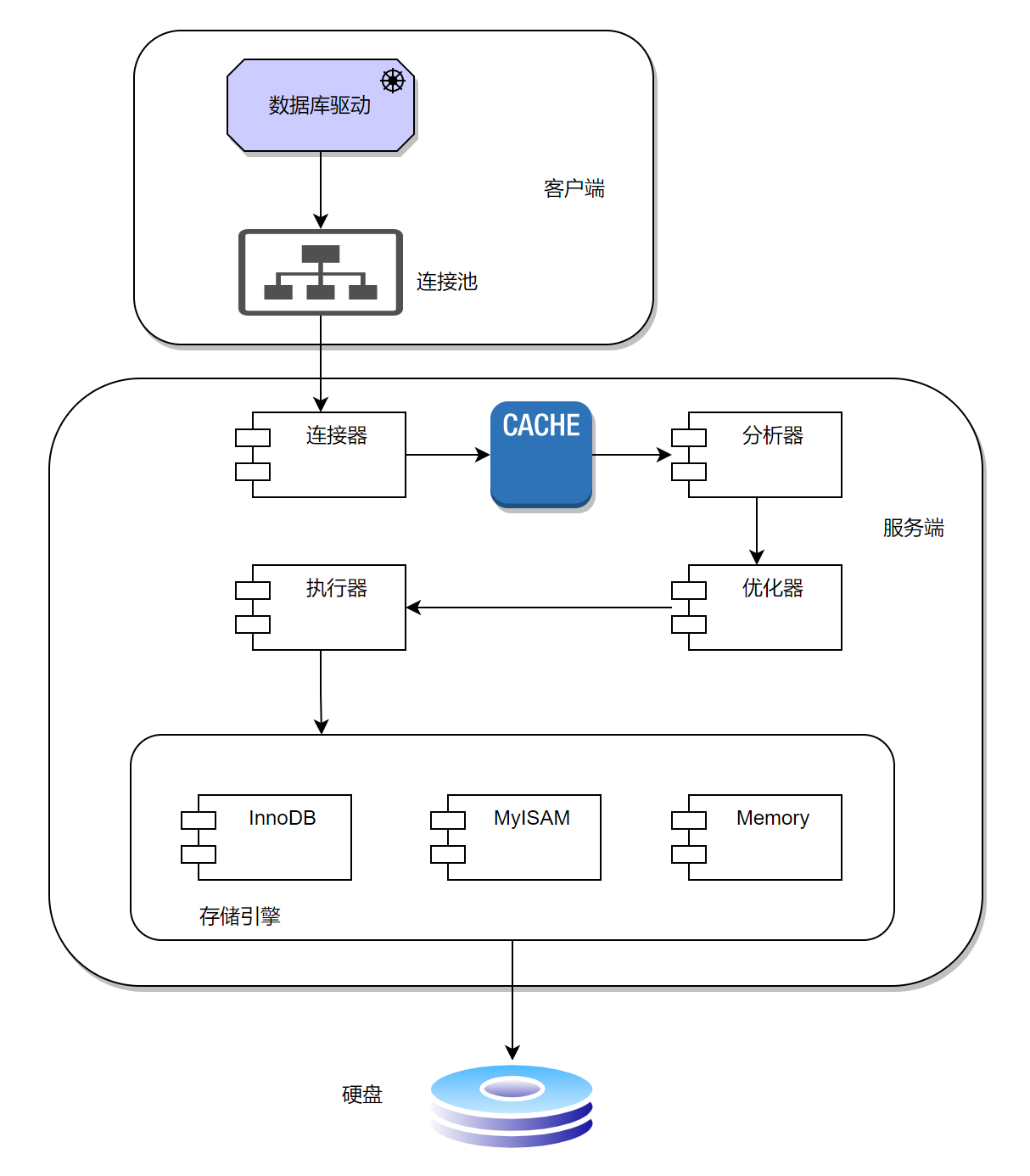
一个完整的数据库服务具备模块如下:
- 客户端
- 数据库驱动
- 连接池
- 服务端
- 连接器
- 分析器
- 优化器
- 执行器
- 存储引擎
详细流程:数据库驱动通过连接池和服务器的连接器相连,当客户端接受到数据时,会将数据发送至服务端,服务端通过连接器接受客户端的数据,需要查询的数据是否在内存中,在内存中则返回,不在内存中则通过分析器分析,分析后交给优化器优化语句为AST tree(抽象语法树)后再交给执行器执行语句,从存储引擎中拉取数据。
1.3 数据库性能测试
在拿到数据库服务后,首先需要针对数据库进行压测,比较常用的压测工具有sysbench,它目前支持主流的Oracle、MySQL和PostgreSQL等数据库。
数据库性能测试指标主要有CPU、内存、磁盘读写率、网络吞吐率几个指标,需要对数据库读写请求成功数和事务完成数有一个大概的估算,在面对高并发的情况时能够合理的分析数据库的负载能力。
2. 数据库优化方式
2.1 优化目标
数据库的优化主要针对与查询中的慢SQL,可以通过打开配置文件中的记录慢SQL功能,针对慢SQL进行统计,找到慢SQL后使用explain关键字对SQL进行解析,结果中的关键字段分别是type(连接类型)、key(查询时使用的索引)、rows(估算出来的结果行数)、Extra(执行情况说明)。
其中需要额外注意type返回的结果,返回结果有ALL、index、range、 ref、eq_ref、const、system、NULL(指当前查询语句的性能从差到好,一般是认为range则是合格),row则是对结果数据条数的估算,该值是越小越好。Extra则是对查询结果的一个说明,其中using where则是说明该查询使用where进行筛选,using index则是触发了索引覆盖即当前查询内容只需要搜索一次索引树即可查到需要的数据,using index condition则是触发回表效率较低。
2.2 数据库查询优化
最左匹配原则:越靠近where的条件,会越有限和索引匹配,当遇到了范围查询(>、<、between)或者like关键字时,会停止命中索引,实际操作中将索引一律靠近where条件即可;
索引选取规范:索引需要区分度较高,区分度的计算公式为(distinct cloumn)/count(cloumn),比率越大则数据越少,一般推荐值为0.1以上;
回表:索引列中未查出select中所需要的字段需要二次进入聚集索引,依据主键查到数据源,相当于经历了两次B+树的搜索,效率很低下,需要避免;索引覆盖则是针对回表的优化,将查询中未命中的索引建立联合索引,避免依据索引无法查出完整数据导致的回表;
索引下推:MySQL5.6优化后查询索引树时会将所有的where判断索引条件都加上,查出结果集,如果不符合结果则直接放弃该条数据。而不是在之前版本中会查出符合第一个where条件的结果再依次使用where条件进行回表查询;
索引合并:MySQL5.1优化后查询可以使用多个索引一起使用;
join原理:
最基础的索引,等于双重for循环,将两张表的内存进行循环然后查询结果集。
当join中的on条件为索引时,会将最外层表的数据查询出来后使用索引去查内层表,顶多只需要三次IO查询索引树即可查到结果;
当join中的on条件不为索引时,会让任意一张表作为驱动表,然后将结果集存入join buffer,然后使用join buffer中的内容扫描另一张表;
join优化:
减少join中的条件数据,减少多次连接,按照机器性能新增join buffer大小;
2.3 数据库存储优化
能用小字段尽量用小字段,varchar是变长的,随着字段存储内容的变多会变长。禁止在数据库内存储文件,如果有需要存储文件的业务时,需要把文件放入文件服务器中供系统访问和下载。
3. 数据库锁和分布式事务
3.1 锁
数据库锁一般是读写锁,读锁后只能加读锁,不能加写锁。加了写锁后其他任何读锁、写锁都无法加入,使用了MVCC机制进行了优化;
InnoDB:有行锁和表锁,有索引则触发行锁,没有则是表锁;
MyISAM:只有表锁;
3.2 事务
事物的四大特征ACID,在InnoDB中:
原子性(Atomicity):使用undo log来实现;
一致性(Consistency):使用A、I、D配合实现;
隔离性(Isolation):使用数据库中的事务隔离级别来实现;
持久性(Durability):使用redo log来实现;
事务隔离级别
- 读未提交:读到对方未提交的事务;
- 读已提交:两次读的内容不同,第二次读到的事务为已提交的内容,也叫不可重复读;
- 可重复读:两次读的内容都是一样的,无论第二次事务有没有提交,只要当前事务未提交,就只能读取当前事务的数据;
- 幻读:第一次只查询到一条数据但是第二次查询查到了另一个事务提交的数据;
- 串行化:事务之间互斥,只有第一个事务提交后后续事务才能依次执行。
MVCC:mysql innodb存储引擎默认隔离级别是可重复读,mysql实现可重复读使用的是mvcc机制(多版本并发控制)。就是在读的时候都加上版本号,只有当其他事务提交后,才更新最新的版本号,实现原理是使用undo log。
分布式事务
CAP定理:
C - Consistency,一致性
A - Availability,可用性
P - Partition tolerance,分区容忍性
CAP定理,由于分布式的存在,所以在三个特性中必须满足P,即分区容忍性,在不同的网络环境中的互相通讯的节点服务死亡后不会影响其他服务。而A和C不能共存,则衍生出来了AP、CP两种情况。
CP:服务和服务之间保证了高强度的一致性,如果有服务死亡则通过投票或选举等措施等待数据同步,服务会有部分时间不可用;
AP:服务和服务之间为了保证可以对外提供访问则会,不关注多台服务上的数据是否同步的情况;
XA规范:
- AP:appliaction 应用程序
- TM:truncation manager 事务管理器
- RM:resource manager 资源管理器
- CRM:communication resource manager 通讯资源管理器
解决方案
- 2PC方案
- 3PC方案
- TCC方案
- 本地消息表方案
- 最终一致性方案
- 最大努力通知方案
4. 分库分表
4.1 概念
分而治之,将大规模的数据按照某种规律进行划分,垂直分表应该在设计表的时候根据业务都划分完毕,所以架构中需要处理的分表主要为水平分表
4.2 相关实现
mysql分区表语法 PARTITION BY RANGE,建议分区列为可阶段性拆分列,例如时间,年龄,类别之类,使用sharding jdbc进行分库分表
5. 高可用
5.1 读写分离
- 待完成
6. Tips
6.1 操作系统相关知识
- 待完成
6.2 Docker部署相关常见问题点
- 时区需要调整到上海
- 默认开启了大小写校验,可按需更改
6.3 数据库连接池
- navicat连接数据库需要把保持连接间隔降低到30s,默认时长为240s,会导致响应时间过长导致数据库连接被释放掉
- 待完成
参考文献:
《MySQL索引原理及慢查询优化》- 美团技术团队